
Sekundärspeicher-Algorithmen
- Typ: Praktikum
- Lehrstuhl: Lehrstuhl Prof. Sanders
- Ort: Raum 211
- Zeit: Vorbesprechung am 26.04.2006, 13.15 - 13.45
- Dozent: P. Sanders, R. Dementiev, D. Schultes, J. Singler
- SWS: 4
- LVNr.: 24872
- Prüfung: Prüfbar
-
Hinweis:
Vorbesprechung am 26.04.2006 13.15 - 13.45 Uhr
Anmeldung bei Frau Seitz, Sekretariat Prof. Sanders, Raum 218, täglich von 9–14 Uhr
Thematik
Massive data sets arise naturally in many domains: geographic information systems, computer graphics, database systems, telecommunication billing systems, network analysis, and scientific computing. Applications working in those domains have to process terabytes of data. However, the internal memories of computers can keep only a small fraction of these huge data sets. During the processing the applications need to access external storage (e.g. hard disks). One such access can be about 106 times slower than a main memory access. For any such access to the hard disk, accesses to the next elements in the external memory are much cheaper. In order to amortize the high cost of a random access one can read or write contiguous chunks of size B. The I/O becomes the main bottleneck for the applications dealing with the large data sets, therefore one tries to minimize the number of I/O operations performed. In order to increase I/O bandwidth, applications use multiple disks, in parallel. In each I/O step the algorithms try to transfer D blocks between the main memory and disks (one block from each disk). This model has been formalized by Vitter and Shriver as Parallel Disk Model (PDM) and is the standard theoretical model for designing and analyzing I/O-efficient algorithms.
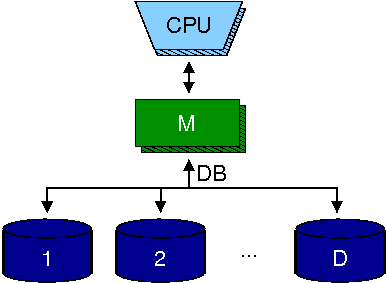
In this praktikum we develop I/O-efficient algorithms that can solve very big problems that do not fit into main memory of a computer. We will use the Stxxl library to implement algorithms and data structures for processing huge graphs, texts and matrices.
| Titel | Bild | Quelle | Kurzbeschreibung |
|---|---|---|---|
| Algorithms for Memory Hierarchies Book | LNCS 2625 Tutorial | ||
| {GUID: 03672EAAD58E4F07A001EB94BD8A99D0} | |||
| STXXL: Standard Template Library for XXL Data Sets | Technical Report 2005/18, Fakultät für Informatik, Universität Karlsruhe |